Napster a popularisé, auprès du grand public, l’échange de fichiers d’utilisateur à utilisateur, c’est-à-dire le peer-to-peer. Cependant, malgré la multiplication de différents systèmes de peer-to-peer, et leur utilisation de plus en plus répandue, le fonctionnement de tout cela reste plutôt méconnu, et souvent mal utilisé.
Si Napster a été massivement utilisé et médiatisé, on a pu constater à l’époque à quel point la notion de peer-to-peer était méconnue : fréquemment on nous parlait de la « musique sur le Web » (alors que Napster ne fonctionne pas par le Web), et les utilisateurs d’autres systèmes moins médiatisés dénonçaient le contresens que représentait l’extrême centralisation de Napster, des petits startupeurs prétendaient avoir découvert des méthodes d’éradication du peer-to-peer par des biais particulièrement tordus (dont la méthode du « nid de coucou »)...
Depuis, les techniques de peer-to-peer ont évolué, les systèmes gagnent en efficacité... surtout, la « fin » de Napster a forcé le grand public à se tourner vers des systèmes désormais très efficaces, et surtout devenus totalement incontrôlables. En tentant de flinguer Napster, les industriels n’auront finalement réussi qu’à encourager le développement de systèmes qui échappent fondamentalement à tout contrôle ; plutôt que retarder une évolution inéluctable, ils l’ont grandement accélérée, et les négociations (notamment sur une rétribution du service, un reversement aux ayant-droits...), qui étaient possibles avec un système centralisé comme Napster, sont devenues totalement impossibles.
Qu’est-ce que le peer-to-peer ?
Le peer-to-peer, simplement, consiste en l’échange direct de fichiers entre utilisateurs du réseau. Pour bien comprendre ce principe, voyons d’abord le principe des serveurs sur l’internet, puis des serveurs personnels.
 Les serveurs sur l’internet
Les serveurs sur l’internet
Pour simplifier à l’extrême, on peut considérer que, dans l’utilisation grand public de l’internet, les services proposés le sont par des machines spécialisées, des serveurs, et que l’utilisateur ne dispose sur sa propre machines que d’outils de consultation (il est « client », au sens informatique). L’utilisateur ne fournit pas de services techniques aux autres utilisateurs, il se contente de consulter une information qui est située en dehors de sa machine ; et s’il veut à son tour fournir de l’information, il l’installe sur un serveur accessible à tous (il ne se contente pas de laisser son ordinateur connecté au réseau en disant aux autres : « venez récupérer ce qui vous intéresse directement sur ma machine »).
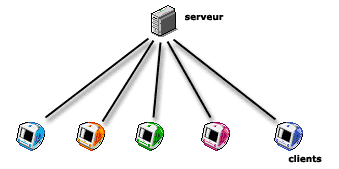
- Un serveur et ses clients
- L’information est disponible uniquement sur le serveur. Pour la consulter, tous les visiteurs (clients) se connectent sur la même machine.
Que ce soit pour un site Web, un serveur FTP (échange de fichiers)..., tout se déroule de manière centralisée sur un serveur. Tous les clients se connectent à ce serveur, et ne communiquent pas directement entre eux. Si les clients ont des contenus à transmettre aux autres utilisateurs, ils doivent les installer sur le serveur central (par exemple envoyer des articles au site, écrire dans les forums, envoyer des fichiers à un serveur FTP...).
Cette méthode offre bien des avantages, puisqu’elle est la plus utilisée sur l’internet... Cependant, elle présente de nombreux inconvénients :
seul le serveur assume le coût économique de la fourniture de l’information (hébergement, bande passante), mais également le risque juridique lié à cette information (risque de procès, notamment pour contrefaçon dans le cas d’échange de fichiers pirates) ;
la « survie » de l’information est extrêmement fragile : il suffit de fermer le serveur (ordre de justice, attaque informatique, problème technique, plus de sous pour payer l’hébergement...) pour que l’information disparaisse ;
les utilisateurs dépendent de la volonté du propriétaire du serveur pour la diffusion de leur information (que ce soit des fichiers ou du contenu) ;
pour savoir où se trouve telle information (c’est-à-dire sur quel serveur), il faut passer par des moteurs de recherche qui (1) ne sont généralement pas adaptés à la nature des informations désirées (dans ce qui nous intéresse, des fichiers), (2) servent également à tracer les contrefacteurs sur le réseau (c’est-à-dire que dès qu’un document est connu du grand public grâce aux moteurs, il l’est également des agents chargés de surveiller ces pratiques).
Pour les échanges de fichiers qui jouent avec la légalité (notamment sur les questions de droits d’auteurs), cette façon de fonctionner est totalement inadaptée (sites fermés, grosses condamnations des webmestres...). Diffuser sa discothèque sur un site Web est certainement une très mauvaise idée.
Les serveurs personnels
Les technologies utilisées par les serveurs de l’internet sont pour la plupart suffisamment simples pour pouvoir être installées sur n’importe quel ordinateur personnel. Chaque utilisateur peut devenir, s’il installe les bons logiciels, un serveur Web, un serveur FTP... sans grande difficulté. Un client devient ainsi un serveur...
Dans le schéma précédent, il suffit donc de remplacer la machine « serveur » par un des clients, qui s’est volontairement transformé en serveur ; les autres clients peuvent désormais se connecter chez lui comme ils le faisaient auparavant avec le serveur spécialisé.
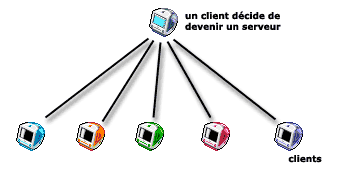
- Un utilisateur transforme son ordinateur personnel en serveur
Cependant, il y a deux inconvénients énormes à ce système :
la grande majorité des connexions grand public à l’internet sont temporaires : vous ne vous connectez que pendant une certaine durée ; de ce fait, votre serveur personnel n’est pas accessible en permanence aux autres utilisateurs ;
il faut faire connaître l’adresse de votre machine aux autres utilisateurs ; pour cela, il suffit de diffuser votre adresse IP (l’adresse du type 192.32.61.125 qui identifie votre machine sur le réseau) ; cependant, dans le cas des connexions grand public, cette adresse est différente à chaque fois que vous vous connectez au réseau.
De ce fait, un service de ce type est particulièrement difficile à gérer avec des connexions grand public. Dans la pratique, les utilisateurs ne créent pas de serveurs Web ou de serveur FTP pour échanger massivement des fichiers de cette façon. Tout cela est trop instable pour être efficace.
Cependant, il existe une alternative à ces problèmes, alternative qui préfigure le véritable peer-to-peer. Un des pionniers de cette méthode a été le système Hotline.
Hotline livre trois logiciels différents aux utilisateurs : un logiciel serveur, qui permet de mettre à la disposition des autres utilisateurs des fichiers de son ordinateur, un logiciel client, qui permet à ces utilisateurs de venir se connecter sur les serveurs Hotline, et enfin un logiciel de centralisation (nommé tracker) qui recense les utilisateurs disposant d’un serveur.
Le système fonctionne de la manière suivante :
lorsqu’un utilisateur installe le serveur sur sa machine, il se signale automatique à un tracker ; ce tracker va donc recenser tous les utilisateurs qui ouvrent leur machine à d’autres utilisateurs ;
pour savoir où trouver des utilisateurs ayant installé un serveur, le client va d’abord se connecter sur un tracker, et récupérer la liste des serveurs Hotline connectés à ce moment ; ensuite, depuis cette liste, il pourra directement se connecter sur le serveur qui l’intéresse.
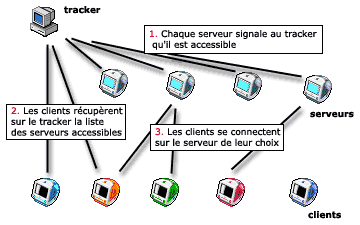
- Le principe de Hotline
On résoud ainsi les deux principaux problèmes des serveurs personnels :
la connexion des serveurs n’est pas forcément permanente, mais leur multiplication et le fait qu’ils sont facilement accessibles permet toujours de se connecter « quelque part », en espérant y trouver les mêmes fichiers ;
les changements d’adresse à chaque connexion des serveurs est résolu par la présence du tracker : à chaque connexion du serveur, celui-ci envoie son adresse au tracker, qui la retransmet aux clients.
Reste le problème du tracker : il faut savoir où il se trouve ; et la fermeture d’un tracker ne doit pas interrompre l’ensemble du système. Pour cela, non seulement le logiciel permettant d’installer un tracker est distribué largement, de plus il existe, à leur tour, des listes de trackers, que les utilisateurs peuvent consulter sur le Web. Voir par exemple le site tracker-tracker.
Cependant, ce principe, s’il est relativement efficace, atteint rapidement ses limites :
le nombre de serveurs est toujours beaucoup plus faible que le nombre de clients ; ainsi, c’est à nouveau un nombre restreint d’utilisateurs qui assume la charge économique et technique du système (bande passante), et le risque juridique ;
de plus, du fait que ce soient des utilisateurs, et non des serveurs spécialisés disposant de connexions à très haut débit, qui fournissent l’information, on voit apparaître un problème propre aux peer-to-peer : les goulets d’étranglement (beaucoup de clients essaient de récupérer de l’information sur une machine qui ne dispose pas d’énormément de bande passante).
Ainsi est apparu le terme leecher, qui désigne les utilisateurs qui récupèrent des fichiers sans jamais en fournir aux autres.
Malgré cela, un tel système donne des résultats convenables, au prix de restrictions importantes :
de nombreux serveurs n’offrent plus un accès libre à tous les utilisateurs, mais réclament un « abonnement », sous la forme de l’envoi d’un fichier pour enrichir la bibliothèque du serveur, ou d’autres méthodes particulièrement navrantes (telles que l’inscription à un site de cul, sur laquelle le serveur touchera un pourcentage) ;
un système de « files d’attente », c’est-à-dire qu’il faut attendre son tour (parfois longtemps) pour pouvoir récupérer le fichier désiré.
Sur le même système, certains utilisateurs préféreront encore se retrancher vers des solutions de niches, pour éviter l’arrivée d’un grand public jugé trop consumériste (trop de clients pour pas assez de serveurs). Ainsi Carracho, disponible uniquement pour Macintosh ; très similaire à Hotline, mais concernant moins d’utilisateurs, d’où moins de difficultés liées à la disproportion entre clients et serveurs.
Le véritable peer-to-peer
Des systèmes comme Hotline et Carracho sont déjà considérés comme du peer-to-peer, puisqu’il s’agit bien d’échange de fichiers directement entre utilisateurs du réseau, sans passer par des machines spécialisées. Cependant, on considère fréquemment qu’un véritable peer-to-peer signifie que tout utilisateur du système est en même temps client et serveur. C’est-à-dire que l’on fait disparaître la différence (marquée notamment par l’utilisation de logiciels différents) entre ceux qui sont clients et ceux qui ont installé le serveur. Avec un système de peer-to-peer, dès que vous utilisez le logiciel client, vous êtes en même temps serveur de vos propres fichiers pour les autres utilisateurs.

- Système peer-to-peer
- Tout utilisateur peut se connecter et récupérer des fichiers sur tous les ordinateurs des autres utilisateurs. Chaque utilisateur est donc à la fois client et serveur.
De cette façon, les contraintes des systèmes précédents sont levées, car il y a potentiellement autant de « serveurs » que de « clients » (chaque utilisateur connecté au système relevant des deux).
Reste la difficulté (énorme, vu le nombre de serveurs potentiels) de savoir où se trouvent les serveurs, et quels fichiers sont disponibles à quel endroit. C’est là, notamment, que se différencient les différents systèmes de peer-to-peer disponibles.
Comment trouver l’information dans un système peer-to-peer ?
Il y a ici deux questions différentes :
quels sont les utilisateurs connectés au système, et où sont-ils (quelle est leur adresse IP) ?
sur quelles machines de quels utilisateurs se trouvent les fichiers qui m’intéressent ?
En réalité, dans les différentes méthodes apportées à ces questions, les solutions répondent aux deux en même temps. Dans les systèmes de peer-to-peer, la solution retenue consistera à la fois à indiquer où se trouvent les utilisateurs fournissant des fichiers, et quels fichiers ils mettent à disposition. (À l’inverse du système de tracker de Hotline, qui se contente de donner l’adresse des serveurs, à charge pour l’utilisateur d’aller consulter ces serveurs pour savoir ce qu’ils contiennent.)
La méthode centralisée
Il s’agit de la méthode retenue par Napster ; elle a assuré son succès, grâce à son extrême facilité d’utilisation et sa très grande rapidité (il suffisait de lancer le programme et d’effectuer une recherche pour obtenir immédiatement le résultat) ; et c’est justement ce qui a causé sa perte...
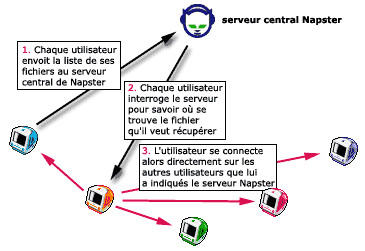
- Le système Napster
Lorsqu’un utilisateur lance le logiciel de Napster, il se signale automatiquement au serveur central de Napster, et lui indique sa propre adresse IP (donc l’adresse à laquelle les autres utilisateurs pourront le joindre) et lui communique la liste complète des fichiers qu’il peut fournir aux autres utilisateurs (dans le cas de Napster, évidemment des fichiers MP3).
De cette façon, le serveur central de Napster connaît en permanence la liste et l’adresse des utilisateurs qui sont connectés en même temps (une fonction d’annuaire), et surtout l’intégralié des fichiers disponibles chez ces utilisateurs. Notez bien : le serveur central de Napster n’héberge pas les fichiers eux-mêmes, il se contente d’en conserver la liste (leur nom, leur taille, et diverses informations propres aux fichiers MP3).
Un autre utilisateur peut alors récupérer ces fichiers. Pour cela, il effectue une recherche (il demande le nom d’un groupe ou le titre d’un morceau) ; cette recherche est effectuée dans la liste des fichiers sur le serveur central de Napster. Immédiatement, ce serveur lui retourne la liste des adresses des autres utilisateurs qui offrent ce fichier. Lorsque cet utilisateur demande le téléchargement du fichier, il ne passe plus par le serveur central, mais se connecte directement chez un autre utilisateur, indiqué par Naspter, et le télécharge directement.
Les avantages de cette méthode sont :
l’extrême simplicité d’utilisation : il n’y a rien à configurer, le logiciel connait l’adresse du serveur central, et s’y connecte automatiquement ;
la très grande rapidité des recherches : tout se déroule sur le serveur de Napster, qui dispose de la liste complète des fichiers disponibles en permanence, et peut donc répondre immédiatement ;
de part son extrême simplicité et la quasi absence de configuration à effectuer, les utilisateurs grand public ne se posent pas la question de savoir s’ils vont fournir ou non des fichiers aux autres utilisateurs ; dans la pratique, dès qu’ils récupèrent un fichier, ils le mettent à leur tour à la disposition des autres utilisateurs. L’attitude consumériste (je récupère des fichiers, mais je n’en fournis pas) est gommée par la pratique très simple du système.
En revanche, les inconvénients d’un tel système sont désormais connus :
il suffit de fermer le serveur central pour que le système cesse de fonctionner ;
le modèle économique aberrant qu’il suppose : en effet, l’extrême centralisation du système était prévue pour que, justement, seul le serveur central puisse gagner de l’argent ; or, techniquement, la charge technique (bande passante, hébergement des fichiers) est partagée par tous les utilisateurs ; demander aux utilisateurs de payer dans un système où ce sont bien eux qui hébergent les fichiers et les fournissent aux autres utilisateurs est idiot. Le peer-to-peer payant est donc une vue de l’esprit.
Le principe du serveur totalement centralisé, s’il est très efficace, ne fonctionne donc pas :
un seul acteur assume un risque juridique énorme ;
ce même acteur trace l’intégralité de l’activité d’utilisateurs qui se livrent à une utilisation qu’ils savent très bien en marge de la légalité, ce qui suppose une belle confiance de leur part ;
un seul acteur prétend s’enrichir dans un système dont le principe est la mutualisation des charges.
Multiplions les centres...
Le système Napster ayant fait long feu, mais son efficacité pratique étant démontrée, on arrive à OpenNap.
Le principe est identique au système Napster, à cette différence essentielle qu’il n’y a plus un seul serveur central, mais un grand nombre, le logiciel serveur étant en effet gratuit. Chaque utilisateur, plutôt que de se connecter uniquement au serveur central Napster, se connecte à une tripotée de serveurs répartis sur l’ensemble de la toile.
De ce fait :
le risque juridique est partagé ; surtout, puisqu’il ne s’agit plus de gagner de l’argent, les serveurs OpenNap sont généralement anonymes, leurs responsables souvent inconnus ;
le système étant open-source (logiciel libre), tout un chacun peut savoir comment il fonctionne, et quelles traces il garde des transactions (donc meilleure confiance quant à une éventuellement utilisation des listes d’utilisateurs) ;
si un serveur est fermé, un autre apparaît ailleurs.
Cette méthode des centres-serveurs qui se multiplient en fonction des besoins est également utilisée par eDonkey, plus spécialisé dans l’échange de films.
L’inconvénient, cette fois, consiste à savoir où se trouvent ces serveurs OpenNap. De la même façon qu’il existe des listes des trackers Hotline, on trouvera des sites recensant les serveurs OpenNap, tels Napigator.
On peut déjà penser qu’en refusant de considérer Napster comme un interlocuteur avec lequel il fallait négocier, l’industrie a accéléré le passage des utilisateurs vers le système OpenNap qui, lui, est totalement incontrôlable : multiplication des serveurs, absence d’interlocuteurs, aucune possibilité de rémunération des ayant-droits... Passer du pire à encore pire.
La méthode décentralisée
À l’inverse de la méthode centralisée de Napster (ou à serveurs centraux multiplies tels OpenNap), le système Gnutella a popularisé une approche totalement décentralisée.
Le principe est d’abandonner totalement l’idée d’un serveur central. Chaque utilisateur parcourt le réseau Gnutella en passant d’un utilisateur connecté à une autre utilisateur, et ainsi de suite.
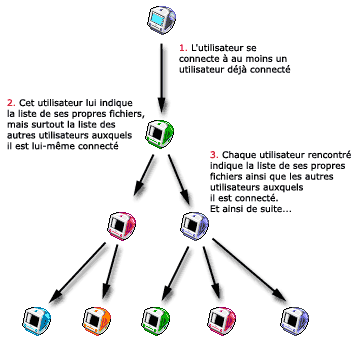
- Le système Gnutella
Il suffit, pour l’utilisateur, de se connecter à un au moins un autre utilisateur déjà connecté au réseau Gnutella. Cet autre utilisateur va alors lui communiquer :
la liste de ses propres fichiers (on sait ainsi quels fichiers sont disponibles, et où il se trouvent) ;
la liste des utilisateurs auxquels il est lui-même connecté.
Le logiciel va alors passer aux utilisateurs communiqués par le premier utilisateurs rencontré, qui vont à leur tour fournir la liste des leurs fichiers, et la liste des utilisateurs qu’ils connaissent. Et ainsi de suite...
La difficulté est alors, dès le départ, de trouver au moins un autre utilisateur connecté. À l’origine, des sites Web fournissaient une liste d’adresses rencontrées récemment sur le système. Désormais, plus simplement, il existe des « utilisateurs » permanents, dont l’adresse est connue, dont l’adresse ne change jamais, et qui servent de points d’entrée systématiques dans le système. Les logiciels utilisant Gnutella commencent donc par se connecter sur ces « utilisateurs » pour ensuite naviguer, de proche en proche, sur le système.
De cette façon, de proche en proche, l’utilisateur parcourt petit à petit le réseau des utilisateurs connectés en même temps que lui, et récupère la liste des fichiers disponibles chez ces utilisateurs. Il peut alors effectuer une recherche dans cette liste, pour savoir où se trouve tel fichier. Lorsqu’il veut récupérer ce fichier, il va alors directement se connecter à l’utilisateur qui le possède (sans parcourir à nouveau tout le réseau, étape qui n’a servit qu’à établir l’annuaire des utilisateurs connectés et la liste des fichiers disponibles).
Pendant ce temps là, évidemment, en tant qu’utilisateur connecté au réseau, il est « visité » par d’autres utilisateurs, qui viendront récupérer chez lui : la liste des fichiers dont il dispose, et la liste des serveurs auxquels il est connecté. Et, éventuellement, ces utilisateurs pourront télécharger les fichiers qu’il fournit au système.
L’avantage de cette méthode, où il n’existe plus aucun serveur central prépondérant dans le système, est évident :
le système ne dépend plus d’un nombre restreint de serveurs assurant un service indispensable à son existence ; il suffit qu’il soit utilisé pour exister...
la charge technique et le risque juridique sont entièrement mutualisés ; aucun membre n’assure par sa nature une charge plus grande que les autres, chacun contribuant en fonction de sa connexion (temps de présence, débit de connexion...).
En revanche, il présente des inconvénients importants :
une certaine lenteur : à chaque utilisation, il faut attendre que l’on ait parcouru le réseau de proche en proche pour récupérer la liste des fichiers avant d’effectuer une recherche (alors qu’avec un système centralisé, on peut le faire dès qu’on se connecte) ; avec une connexion lente (modem), ce délais peut être important ;
une grande inefficacité : une bonne partie des données échangées ne consiste qu’à fournir des listes de fichiers (fichiers qui ne seront dans leur immense majorité pas téléchargés) ;
une grosse proportion de leechers, c’est-à-dire d’utilisateurs qui récupèrent des fichiers sans jamais en fournir, d’où une dissymétrie dans la mutualisation du service.
Notez bien : il existe de nombreux logiciels, aux noms et aux interfaces très différents, exploitant le réseau Gnutella. Cependant, à partir du moment où ces programmes exploitent Gnutella, l’utilisation de l’un ou de l’autre ne change rien : c’est bien au même réseau de machines que l’on accède (il n’y a pas un réseau différent pour chaque logiciel).
Les inconvénients du peer-to-peer et les remèdes
Le peer-to-peer est séduisant dans son principe, mais certains de ses inconvénients étaient rédhibitoires. D’où certainement le succès d’un système aberrant comme Napster. Honnêtement, utiliser Gnutella avec un modem à l’époque de Napster et Hotline, même si cela semblait particulièrement élégant, n’était pas une partie de plaisir : grande lenteur avant de pouvoir effectuer une recherche pertinente, téléchargements avortés... à comparer à la facilité d’utilisation des autres systèmes.
Cependant, tout cela a beaucoup évolué, évolue encore, et l’utilisation devient réellement agréable. Avec une connexion à haut débit (câble ou ADSL), les résultats sont même stupéfiants : un vrai bonheur pour l’utilisateur, un véritable cauchemar pour ceux qui vivent des droits de la proriété intellectuelle. Il s’agit certainement de l’un des secteurs qui évolue le plus vite sur le réseau, à la fois pour des raisons de programmation et d’attention des utilisateurs (depuis la disparition de Napster, les systèmes alternatifs se développent nettement plus vite) que des raisons purement techniques (la multiplication des accès à haut débit chez les particuliers).
Voici quelques unes des évolutions notables des systèmes de peer-to-peer [1]...
Franchir le mur du modem
Une des principales difficultés du peer-to-peer est la présence (majoritaire) d’utilisateurs connectés avec des modems. Cela pose deux problèmes :
parcourir le réseau en passant de modem en modem est extrêmement lent ; même une information aussi « courte » qu’une liste de fichiers et une liste d’utilisateurs connectés prend du temps ; une fois parti dans un réseau constitué de modems, l’utilisateur perd énormément de temps ;
or il est illusoire de vouloir récupérer un gros fichier chez un utilisateur connecté avec un modem, car les temps de téléchargement seront interminables (et l’utilisateur sera certainement déconnecté dans peu temps pour ne pas se ruiner en facture de téléphone).
Avec l’arrivée du grand public, la proportion entre utilisateurs ayant un très fort débit et utilisateurs de modem était devenue telle que la structure du réseau Gnutella était compromise : trop de « culs de sac » (les modems) bloquaient le système.
Le système fut donc repensé, pour établir une hiérachie technique entre les utilisateurs : les utilisateurs à très haut débit (lignes spécialisées T1 et T3) se connectant prioritairement entre elles, puis les utilisateurs de l’ADSL aux lignes haut débit et aux autres utilisateurs ADSL, et enfin les utilisateurs de modems à la périphérie du système. Attention, il ne s’agit pas d’exclure les utilisateurs de modems ; au contraire, il s’agit de privilégier, pour tous les utilisateurs, un référencement de proche en proche plus rapide qui profite à tous. Les lignes à très haut débit se référencent d’abord entre elles, donc très rapidement ; les utilisateurs ADSL profitent donc de ces informations, puis partent dans les secteurs moins rapides ; enfin, les utilisateurs de modems profitent de toutes ces informations. L’intérêt est que le parcours du réseau se fasse prioritairement par les lignes les plus rapides, plutôt que d’aller se perdre dans l’interrogation des modems.
La seconde innovation fut d’éviter totalement l’interrogation des ordinateurs connectés par modem. Pour cela, certains utilisateurs disposant d’un haut débit (à partir de l’ADSL) référencent eux-mêmes les utilisateurs connectés par modem. Lorsqu’un autre utilisateur arrive sur ces machines, elles récupèrent la liste des fichiers des utilisateurs de modems qui s’y sont connectés, sans devoir aller interroger le modem lui-même.
En quelques mois, le confort d’utilisation du réseau Gnutella a ainsi été incroyablement amélioré. Le changement d’échelle (d’un système relativement réservé à certains utilisateurs au grand public) ne pose plus les problèmes qui ont été rencontrés durant l’année 2000. Alors qu’il fallait attendre plusieurs dizaines de minutes avant d’effectuer la moindre recherche, on récupère désormais une liste fichiers exploitable en quelques secondes, et on obtient une liste énorme en quelques minutes.
Assurer les téléchargements
Une épreuve pénible attendait encore les utilisateurs du peer-to-peer : les refus de téléchargement, des vitesse de téléchargement minuscules, et des interruptions au milieu du transfert. On avait parcouru le réseau, situé l’emplacement des fichiers désirés, mais leur récupération était impossible...
Une première raison, durant l’année 2000, était l’instabilité de logiciels Gnutella mal programmés. Évidemment, si le logiciel plante, le téléchargement est interrompu... Le développement des logiciels, ainsi que la meilleure stabilité des systèmes d’exploitation des ordinateurs personnels dans la gestion des requêtes internet, ont largement résolu ce problème.
Il y eu ensuite la multiplication des sites Web permettant de récupérer des fichiers du réseau Gnutella directement par le Web. Évidemment, de part leur grande facilité d’utilisation (aussi simple que Napster, puisqu’on interrogeait directement un serveur Web plutôt que de parcourir le réseau de proche en proche), ces systèmes ont eu un énorme succès ; en revanche, leurs utilisateurs ne fournissaient aucun service au système (notamment, ils n’offraient aucun fichier aux autres utilisateurs). D’où une énorme disproportion entre des utilisateurs totalement consommateurs, et ceux qui participaient activement à la mutualisation. Schéma classique : peu de lieux fournissant des fichiers, et beaucoup d’utilisateurs en récupérant. Ainsi, de trop nombreux téléchargement étaient assurés par pas assez d’utilisateurs, le système était bloqué. Depuis, les logiciels Gnutella interdisent tout simplement l’interrogation depuis des systèmes qui ne participent pas au système. Pour « faire » du Gnutella, il faut donc utiliser un logiciel Gnutella, et ne plus passer par le Web.
Globalement, il y a toujours beaucoup d’utilisateurs qui récupèrent des fichiers, mais n’en fournissent pas au réseau. Une première solution toute simple : par défaut, les logiciels sont désormais configurés pour que tous les fichiers téléchargés soient automatiquement mis à disposition des autres utilisateurs ; pour ne pas fournir de fichiers, il faut donc modifier la configuration de son logiciel. Opération qui est très simple, cependant beaucoup d’utilisateurs laissent le réglage pas défaut... Pour le reste, il faudra sans doute compter sur la pédagogie : comprendre le peer-to-peer, et pourquoi, techniquement, on ne peut pas se permettre de rester consommateur (ce qui n’est pas le cas, par exemple, du Web : on peut rester passif sur le Web ; c’est dommage, mais techniquement cela est indifférent pour l’état du réseau).
Enfin, de gros efforts ont porté dans la programmation des logiciels pour résoudre le problème des transferts interrompus. Des logiciels comme LimeWire ou eDonkey sont d’ailleurs remarquables de ce point de vue.
Tout d’abord, la plupart des logiciels sont capables de reprendre un téléchargement interrompu (ce qui n’était pas le cas avec Napster).
Les logiciels les plus efficaces sont capables de télécharger un même fichier sur plusieurs ordinateurs à la fois ; par exemple, si un fichier est disponible sur une dizaine de serveurs différents, il sera récupéré (par petits bouts) en même temps sur les quatre ou cinq plus rapides ; cela assure un débit élevé malgré la charge de certains serveurs, et résoud le problème de l’assymétrie des connexions.
Lorsqu’il n’y a plus d’ordinateurs identifiés disposant du logiciel en cours de téléchargement, le logiciel relance lui-même une recherche sur le réseau, pour trouver d’autres ordinateurs disposant de ce fichier, et reprend automatiquement le transfert si nécessaire.
Résoudre l’imprécision des recherches
On recherche, avec le peer-to-peer, des fichiers. La recherche est donc effectuée sur le nom du fichier, souvent peu explicite. Par rapport à une recherche dans un moteur Web, où l’on peut affiner sa recherche en fonction du contenu du document, ici on dispose de très peu d’éléments pour déterminer finement l’objet de l’information.
On obtient ainsi souvent beaucoup de réponses pour peu de documents pertinents ; ou bien des recherches trop précises qui ne donnent aucun résultat.
Une solution (étonnante ?) que la pratique a fait apparaître : la spécialisation des différents systèmes de peer-to-peer. Même si, en dehors de Napster, tous les systèmes de peer-to-peer permettent d’échanger tous types de documents, les utilisateurs se sont mis à utiliser l’un ou l’autre de manière thématique, et parfois à abondonner les systèmes trop généraux. Ainsi Carracho est devenu une plateforme de prédilection pour l’échange de logiciels Mac, à partir du moment où l’on a trouvé « trop » de fichiers pour Windows et d’images de cul sur Hotline ; ou bien eDonkey privilégié pour l’échange de vidéos au format Divx... Il est ainsi fréquent que le choix d’un logiciel ne dépende pas tant de ses fonctionnalités que du thème général des fichiers que les utilisateurs ont choisi d’y échanger. On ne privilégie pas forcément le système qui a le plus grand nombre d’utilisateurs, mais celui dont la thématique des fichiers correspond le mieux à ses besoins.
Évidemment, les logiciels permettent de sélectionner automatiquement un type de fichier, en associant à chaque type la terminaison du nom du fichier : MP3 pour la musique, SIT pour les logiciels Macintosh, EXE pour les logiciels Windows, etc. C’est tout con, mais c’est pratique...
Une évolution probable sera la possibilité d’associer une description précise de chaque fichier (dans un fichier annexe en XML, directement géré par le logiciel de peer-to-peer). Ainsi, pour un film, le titre exact du film, le nom du réalisateur et des principaux acteurs, la qualité de l’encodage, etc.
Quelques conseils d’utilisation
Terminons par quelques conseils pour les utilisateurs. En effet, les systèmes de peer-to-peer ne sont viables que lorsque la plus grande proportion d’utilisateurs est active, et non simplement consommatrice. De plus, participer n’est pas forcément suffisant, il faut « bien » participer pour que le système fonctionne ; malgré la bonne volonté, certains comportements sont contre-productifs.
Ce point est important : pour la plupart des services de l’internet, la participation active des utilisateurs n’a aucun impact technique sur le réseau. À l’inverse, dans le peer-to-peer, une attitude consumériste des utilisateurs nuit techniquement au système. Vous pouvez passer votre journée sur uZine sans jamais proposer d’article ni poster dans les forums, techniquement cela est indifférent pour le Web ; en revanche si vous écumez un système de peer-to-peer sans jamais rien fournir, l’infrastructure technique du système est compromise.
Bien connaître et bien régler ses logiciels de peer-to-peer
Le meilleur moyen de « bien » participer est encore de bien connaître les caractéristiques des systèmes que l’on utilise. Prenez le temps de lire, au minimum, la FAQ des logiciels de peer-to-peer, pour éviter les erreurs les plus fréquentes.
Si un système est utilisé par les autres utilisateurs selon un thème spécifique, respectez ce thème, et ne fournissez pas sur ce réseau des fichiers non appropriés. S’il s’agit d’un réseau de musique, fournissez uniquement de la musique ; fournissez des films sur un réseau de films...
Réglez correctement votre logiciel. Généralement, le minimum est d’indiquer quel type de connexion vous utilisez (les autres paramètres se régleront automatiquement). Il ne sert à rien ici de « tricher » (indiquer un ligne T1 alors que vous avez un modem), bien au contraire. Bien réglé, le système sera non seulement optimisé pour les autres utilisateurs, mais également pour vous. Si vous « trichez » sur votre connexion, vous perturberez le réseau et vous vous retrouverez avec dix utilisateurs connectés à très haut débit depuis leur université en train de tirer sur votre petit modem. Et, non, ça ne fait pas plus classieux d’annoncer une ligne haut débit quand on a un modem ; non, ça ne vous fera pas récupérer plus de fichiers plus vite.
Quels fichiers partager ?
Le choix des fichiers à partager est évidemment primordial pour un bon fonctionnement du réseau.
Tout d’abord, ne culpabilisez pas parce que vous ne fournissez pas beaucoup de fichiers, ni de gros fichiers, avec votre connexion par modem. Évidemment, vous serez un leecher, mais techniquement vous n’y pouvez pas grand chose. Inutile en effet de proposer 10 fichiers de 100 Mo si, pour les télécharger depuis chez vous, il fallait une bonne semaine aux autres usagers du service, alors que vous vous déconnecterez au bout d’une demi-heure.
Le plus simple est de laisser à disposition des autres utilisateurs les fichiers que vous avez vous-même récupérés. En y ajoutant si nécessaire une poignée de fichiers personnels inédits. C’est sans doute ainsi que, par la pratique, vous obtiendrez un bon équilibre. En effet, le nombre et la taille de fichiers que vous mettrez à disposition correspondra, grosso modo, au temps que vous passez en ligne sur ce système. De plus, dans le choix qualitatif, cela correspondra à des fichiers qui vous intéressent, donc qui intéressent d’autres utilisateurs ; pour des fichiers rares, hé bien vous serez seulement quelques uns à les proposer, mais tout aussi peu nombreux à les réclamer ; pour des fichiers très répandus, justement il est intéressant qu’ils soient répandus, puisque très demandés. Inutile donc d’effectuer une sélection très élaborée en voulant orienter les goûts de vos contemporains ; le but est d’obtenir un équilibre technique entre l’offre et la demande de fichiers. Équilibre obtenu simplement en fournissant les fichiers qui vous ont intéressé.
Vérifiez les fichiers que vous proposez au téléchargement, et virez les fichiers qui ne fonctionnent pas (le critère est simple : si ça ne fonctionne pas chez vous, ne distribuez pas le fichier ; n’espérez pas que quelqu’un d’autre saura le faire fonctionner... il est trop pénible de récupérer un fichier de 70 Mo pour se rendre compte qu’il ne fonctionne pas). Le but n’est pas de proposer le maximum de fichiers, mais de proposer des fichiers qui fonctionnent. Si une démo a atteint sa date de péremption, virez-là ; si un fichier musical est inaudible, effacez-le ; s’il y a un virus, détruisez le fichier. Ne pensez pas que quelqu’un saura mieux l’utiliser que vous ; au contraire, si ça ne fonctionne pas pour vous, considérez que ça ne fonctionnera pour personne. Dans le peer-to-peer, l’autorité de certification de la validité des fichiers, c’est vous.
À ce sujet, revenons sur la technique du « nid de coucou ». Il s’agirait, pour certains ambitieux branleurs qui n’ont pas encore renoncé aux charmes de la nouvelle économie, de contrecarrer la contrefaçon en diffusant massivement des fichiers corrompus (notamment des fichiers musicaux qui ne contiennent que du bruit, mais avec le même nom de fichier que d’autres fichiers MP3). C’est totalement imbécile, parce qu’il est impossible de diffuser massivement un fichier corrompu via le peer-to-peer : en effet, si vous récupérez un fichier inaudible, contentez-vous de l’effacer et de ne pas le rediffuser ; en revanche, au téléchargement suivant, vous récupérerez le bon fichier, que vous pourrez à votre tour mettre à disposition ; ainsi la proportion de bons fichiers écrase celle de mauvais fichiers.
Par pitié, pas de fichiers de cul ! Ou alors, faites-en de grosses archives. Il ne s’agit pas ici d’un point de vue moraliste, je n’ai rien contre les images de cul. En revanche, elles n’ont rien à faire sur le peer-to-peer ; le Web et les newsgroups spécialisés se prêtent très bien à leur diffusion. Les « portfolio » d’images de cul se diffusent très mal par peer-to-peer, et cela bouffe énormément de temps de part la profusion de petits fichiers aux noms pas du tout explicite ; votre collection de photos de Pamela Anderson est ici inexploitable : on va récupérer une liste de 2000 noms de fichiers du style « Pam24.png », « pamela-big-143.png », très longue à charger, mais qui ne correspondra à aucune recherche utile (car à « Pamela Anderson », vos fichiers n’apparaîtront pas ; et si au contraire on tape « pam », on obtiendra 20000 fichiers différents, la plupart n’ayant aucun rapport avec Alerte à Malibu). Si vous voulez absolument diffuser vos photos, au moins faites en une grosse archive (un fichier unique par paquet de 500), avec un nom très explicite (« Pamela Anderson gallery (1-500).zip »).
Surveillez votre facture
Je suppose qu’il n’est pas nécessaire de vous le rappeler ; mais comme un accident est si vite arrivé...
Si vous avez un modem, le peer-to-peer peut coûter très cher. Il vaut peut-être mieux acheter un album que le récupérer en MP3 par modem au milieu de l’après-midi. Même chose pour les jeux (surtout que vous risquez de passer votre semaine à essayer de récupérer un fichier de 100 Mo qui ne sera finalement pas exécutable).
Si vous avez une connexion par le câble, vérifiez que votre fournisseur d’accès n’a pas limité la quantité de données que vous pouvez émettre. Si c’est le cas, soit désactivez totalement la possibilité pour d’autres utilisateurs de récupérer des fichiers chez vous ; soit utilisez un utilitaire qui bloquera ces upload lorsque vous approcherez de la limite fatidique. En effet, les méga-octets supplémentaires risquent de vous être facturés très cher, et vous n’avez pas envie de payer pour 5 000 euros de connexion internet parce que vous avez voulu faire plaisir à la communauté...
Le peer-to-peer, c’est gratuit
Enfin, n’acceptez jamais de payer pour participer à un réseau peer-to-peer. En effet, dans un tel système, c’est vous qui fournissez la bande passante, qui éventuellement assumez le risque juridique, qui ouvrez votre disque dur pour d’autres utilisateurs... Il n’est donc pas question de payer un abonnement à un prestataire qui en fournit aucun autre service que d’encaisser votre carte bleue.
Donc, jamais d’abonnement pour participer à du peer-to-peer.
En revanche, vous pouvez très bien payer, ponctuellement, pour un logiciel aux fonctionnalités particulièrement bien pensées (en gardant à l’esprit que ça ne doit pas être trop cher, et que la plupart des technologies utilisées sont diffusées en logiciel libre).







